Signal-to-Noise Is an Infrastructure Problem, Not a Filtering Problem
Most intelligence teams filter noise at the report layer — reviewing 50 signals and discarding 40. That's not a workflow. It's a symptom of bad ingestion architecture. The fix happens upstream, not downstream.
Every intelligence team I've spoken with has the same complaint: too much noise, not enough signal. They describe the same ritual — pull a report, scan 50 items, throw out 40, brief leadership on the remaining 10. Repeat weekly.
They think this is a filtering problem. It isn't. It's an infrastructure problem, and the distinction matters enormously.
The Traditional Approach and Why It Fails
The default CI workflow is additive by design. Teams start by subscribing to every potentially relevant source: news aggregators, social listening platforms, competitor RSS feeds, patent databases, job boards, analyst reports. The logic is sound in isolation — you don't want to miss something important, so you cast a wide net.
The catch is what happens downstream. Every signal that enters your pipeline eventually reaches a human reviewer. That reviewer is now performing triage: relevant or irrelevant, high-confidence or speculative, actionable or ambient. At 50 signals per cycle that's manageable. At 200 it's a part-time job. At 500 it's a full-time job that crowds out the actual analysis work.
But there's a subtler failure mode than workload. It's cognitive contamination.
When analysts review and discard noisy signals, they tell themselves the discarded data isn't influencing their conclusions. That's not how cognition works. Exposure to a signal — even one you consciously reject — primes the analytical frame you bring to the signals you keep. You've already been influenced by the noise before you filter it out. The act of filtering happens too late in the process to prevent that influence.
This is confirmation bias operating at the architecture level, not the individual level.
The Infrastructure Reframe
Here's the shift in perspective: filtering is not an analysis task. Filtering is an ingestion task.
The question "is this signal relevant to our intelligence objectives?" should be answered at the moment of data entry — at the source qualification layer — not at the moment of reporting. If a source consistently produces signals that don't meet your confidence or relevance thresholds, that source should never enter your pipeline in the first place.
This reframe has radical implications for how you build your intelligence function. Instead of asking "how do we review this efficiently?", you ask "why is this entering the system at all?"
A Concrete Example: The Trading Bot Case
The clearest example I have of this comes from our InDecision framework — the quantitative model we use for crypto market analysis. The framework generates directional signals with confidence scores. Early in its architecture, we had a bias injection layer that applied market-directional adjustments to all signals passing through it.
The problem: the bias layer was executing on ambiguous signals — cases where the spread between bullish and bearish evidence was less than 8 percentage points. These weren't high-conviction reads. They were noise dressed up in numerical clothing. The bias injection was essentially amplifying uncertain inputs, which cascaded downstream into our position sizing and timing logic.
The fix wasn't to add a post-processing filter that said "ignore signals where spread was low." The fix was to gate at the computation layer itself — before the bias adjustment executes, check whether the spread meets a minimum confidence threshold. Below the gate, no bias injection occurs. The ambiguous signal passes through unmodified and gets handled appropriately at a later stage that's designed for uncertainty.
The downstream improvement was immediate. The analysis layer received cleaner inputs. Position confidence scores became more reliable. False positives dropped.
The insight transfers directly to competitive intelligence.
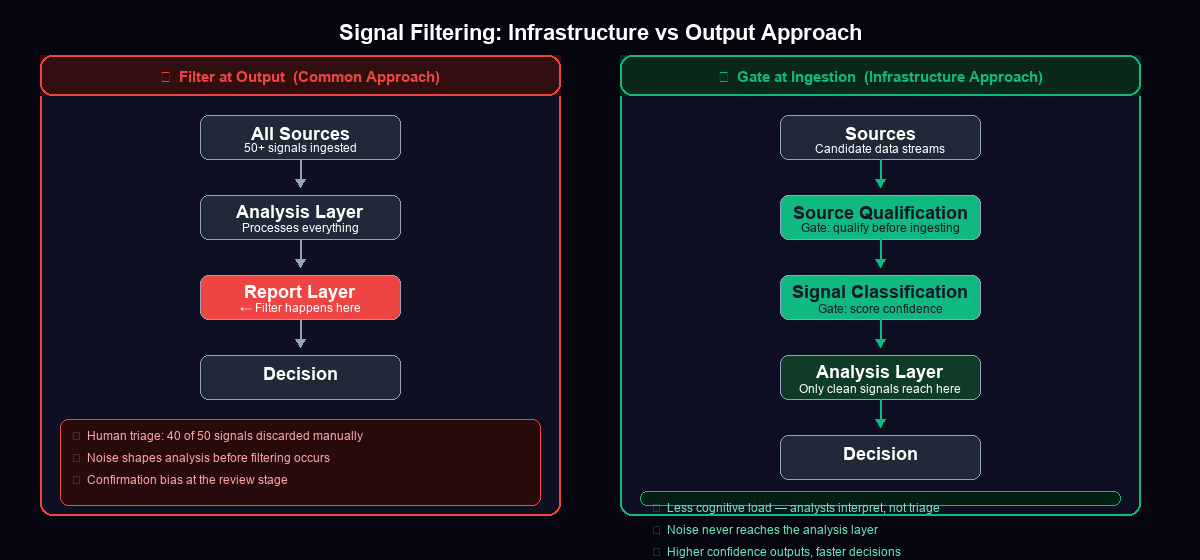
The Three-Layer Architecture
A well-built CI infrastructure separates the work into three distinct layers, each with its own gating logic.
Layer 1: Source Qualification
Before any source enters your intelligence pipeline, it goes through qualification. This is not a one-time exercise — it's an ongoing assessment. You're asking: Does this source produce signals that meet our relevance criteria with sufficient frequency? Does this source have a track record of accuracy? Does this source have a bias (competitive, commercial, ideological) that we need to account for?
Sources that fail qualification don't get ingested. They don't get added to a "low priority" queue that someone will get to eventually. They're excluded. This is a hard gate, not a soft preference.
Layer 2: Signal Classification
Signals that pass source qualification still vary in quality and relevance. At the classification layer, you're applying structured criteria to each signal before it reaches an analyst: confidence level (high/medium/low based on corroboration), relevance score (does this map to a current intelligence priority?), and signal type (confirmatory, contradictory, novel, ambient).
The key gate here is confidence. Signals below a confidence threshold don't reach the analysis layer. They're logged, categorized, and retained for pattern analysis — but they don't become intelligence inputs until additional corroboration arrives that elevates them.
Layer 3: Analysis Gate
The analysis layer receives only pre-qualified, pre-classified signals. Analysts are not doing triage here. They're doing interpretation. This is the layer where human judgment is most valuable — connecting signals, identifying implications, building narratives — and it should be protected from noise by the two layers above it.
The analysis gate handles edge cases: signals that are classified as high-confidence but don't fit existing frameworks, contradictory signals from qualified sources, and novel signals that may require adjusting the intelligence priorities themselves.
What to Stop Doing
Stop subscribing to sources "just in case." Every low-confidence source you add to your pipeline shifts analyst time toward triage and away from analysis. The marginal benefit of a rarely-useful source is exceeded by the cost of reviewing it continuously.
Stop treating large signal volumes as a sign of thoroughness. Volume is not quality. A CI function that reviews 200 signals per week is not twice as good as one that reviews 100. It might be half as good, if those extra 100 signals are diluting the cognitive bandwidth applied to the meaningful ones.
Stop filtering at the dashboard level. If your final intelligence deliverable requires a human to manually exclude irrelevant items before reading it, you haven't built a filtering system — you've built a sorting system with extra steps.
What to Start Doing
Qualify sources before ingesting them. Define explicit criteria: minimum relevance hit rate, track record window, bias documentation. Run prospective sources through qualification for 30 days before adding them to your live pipeline.
Classify signals by confidence before they reach analysts. Build or configure your tooling to score incoming signals automatically. The classification doesn't have to be perfect — it has to be good enough to separate high-confidence signals from ambiguous ones before a human sees them.
Gate ambiguous intel at the architecture level, not the review level. Low-confidence signals should enter a holding pattern with explicit corroboration requirements. They shouldn't be in the same inbox as your high-confidence signals, implicitly competing for analyst attention.
The Compounding Effect
Here's the reason this matters beyond workflow efficiency: intelligence quality compounds when the inputs are clean.
When analysts spend their time interpreting pre-qualified, pre-classified signals, they build pattern recognition on high-quality data. Their intuitions become more accurate over time because they're calibrated against real signal, not noise. The confidence in their assessments increases because the assessments are built on a foundation that's been architecturally defended against contamination.
The teams that do competitive intelligence well aren't just smarter or harder-working. They've built infrastructure that makes the right inputs easier to access and the wrong inputs harder to encounter. The filter isn't in the analyst's head. It's in the system.
That's the shift. Signal-to-noise is an infrastructure problem. Solve it at the source.
Explore the Invictus Labs Ecosystem

2026-03-09 · 7 min
AI Signal Post-Mortems: The Competitive Intelligence Methodology Most Systems Skip

2026-03-09 · 6 min
Hot Reload and the Execution Gap: What Continuous Deployment Means for Live Alpha

2026-03-09 · 6 min
The Automated Signal Surface: What AI-Generated Visual Intelligence Reveals About Competitive Infrastructure
Follow the Signal
Intelligence dispatches, system breakdowns, and strategic thinking — follow along before the mainstream catches on.